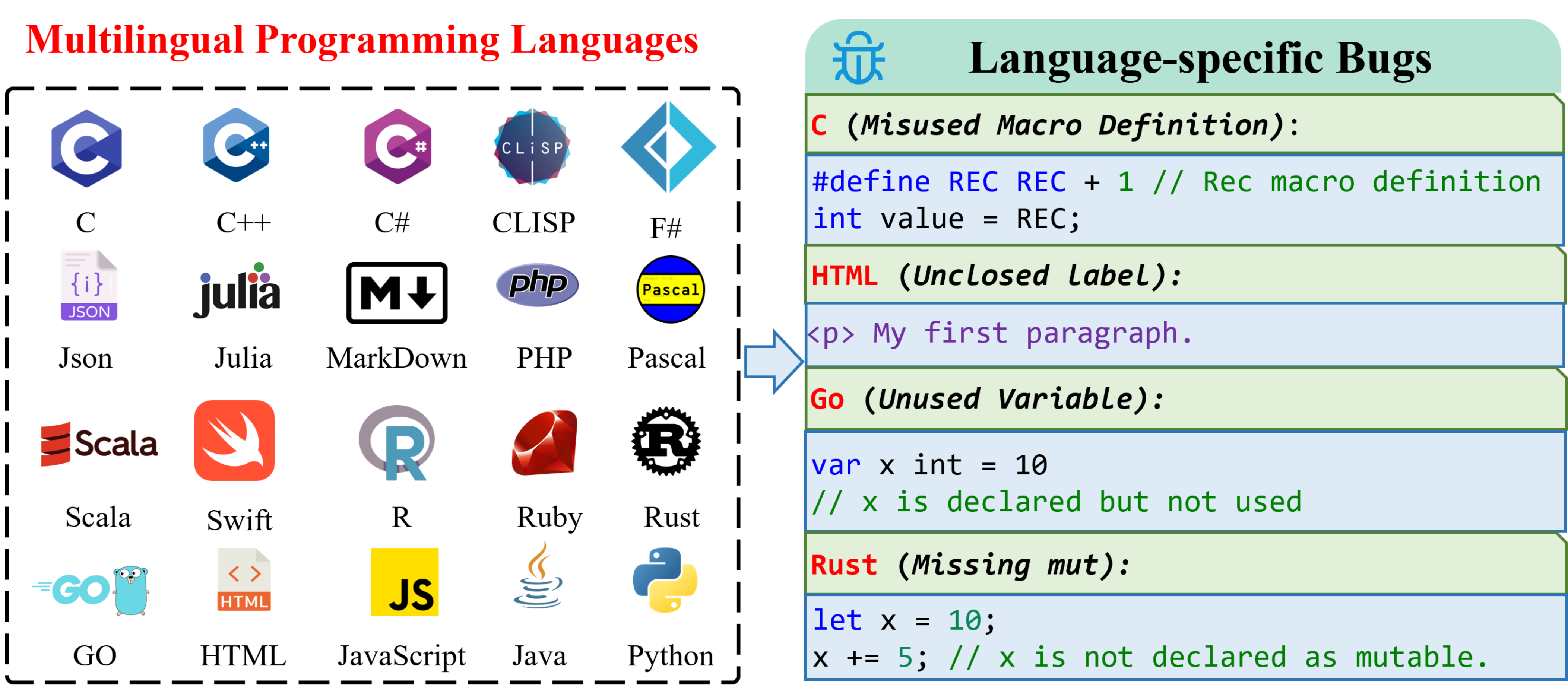
To advance the field of multilingual debugging with LLMs, we propose the first massively multilingual debugging benchmark, which includes 3.9K test samples of 20 programming languages and covers the automated program repair (APR) task, the bug localization (BI) task, and the bug identification (BI) task.
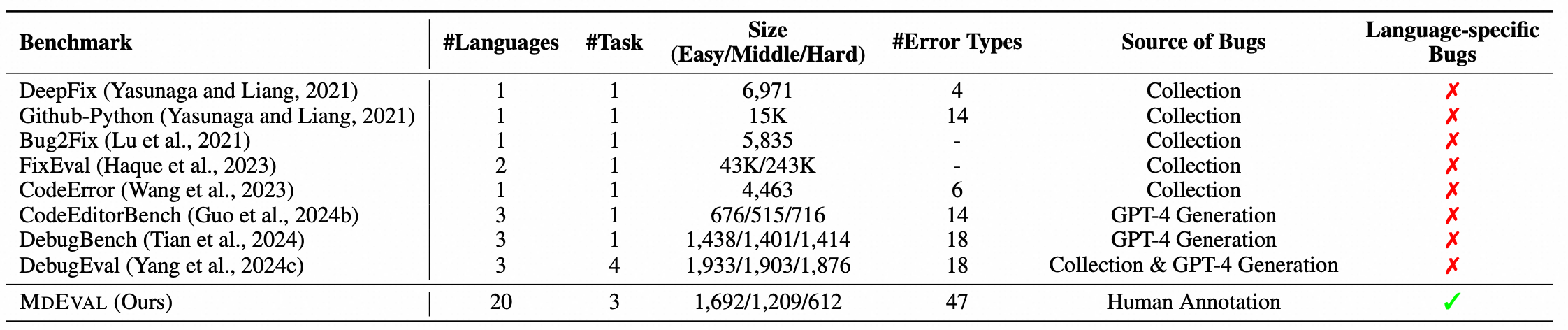
Comparison between MdEval and other code debugging benchmarks. MdEval significantly provides a comprehensive multilingual view by expanding the variety of programming languages and language-specific error types.

Error types in MdEval. Part (a) shows generic error types, and Part (b) lists language-specific error types.
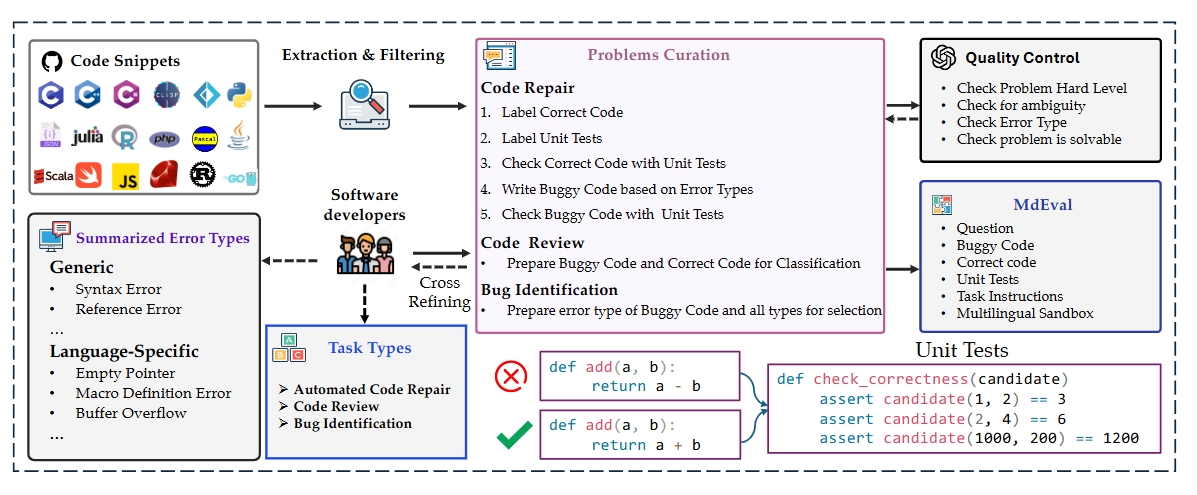
We collected and filtered code snippets from GitHub. Before annotation, we summarized error types. Annotators then labeled the code based on these types. To ensure quality, they used GPT-4o to evaluate the annotations on four criteria: difficulty, ambiguity, error type, and solvable. Finally, they exchanged data with each other to minimize bias and errors.
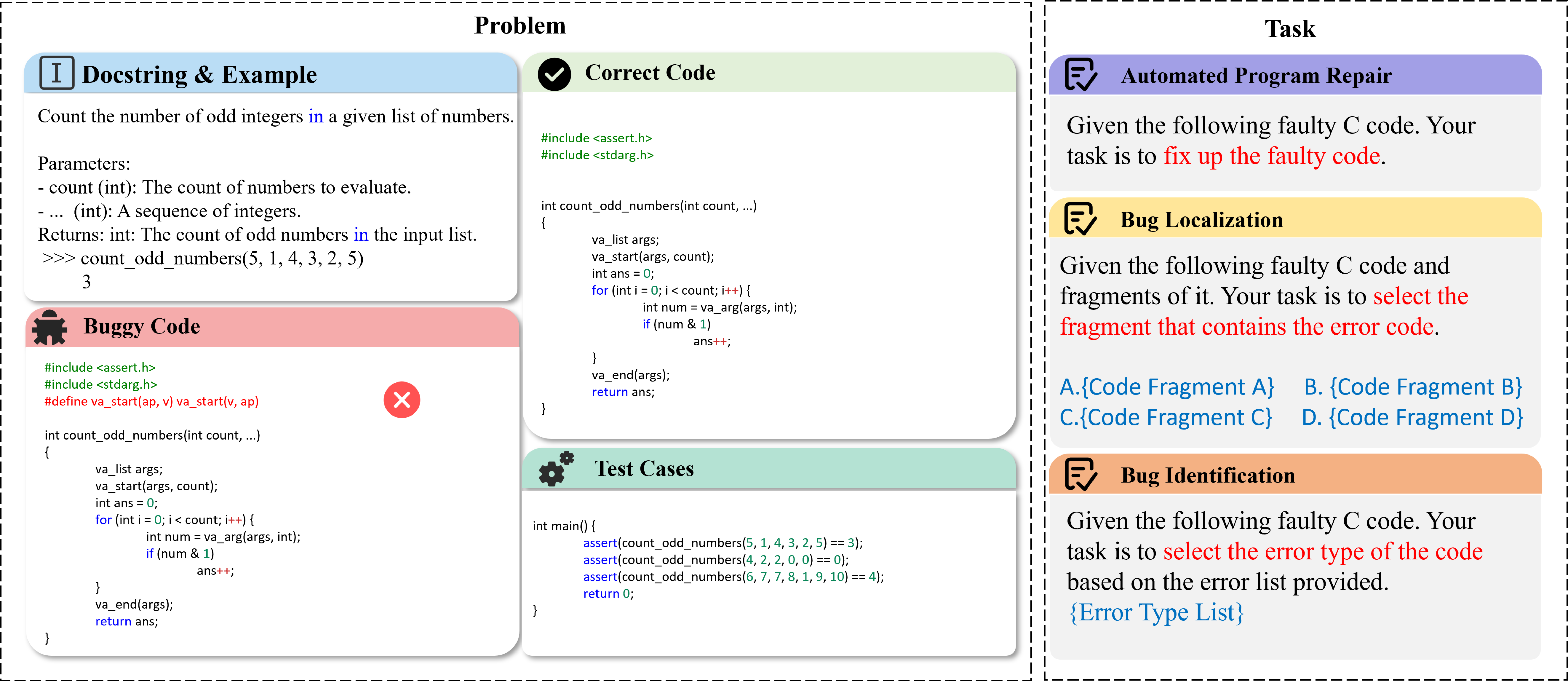
Examples of multilingual automated program repair (APR), bug localization (BI), and bug identification (BI).
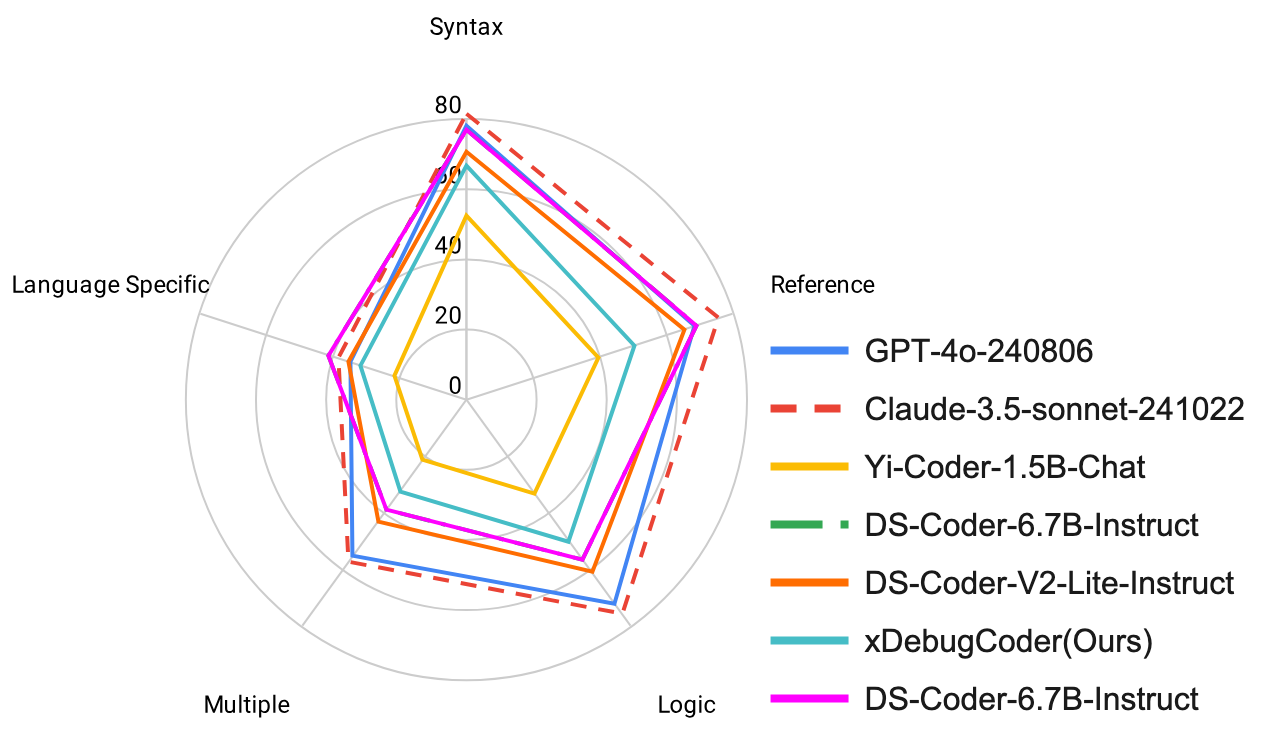
The performance of models on the automated program repair task varies across different error types, highlighting the strengths and weaknesses of these models in addressing specific challenges.
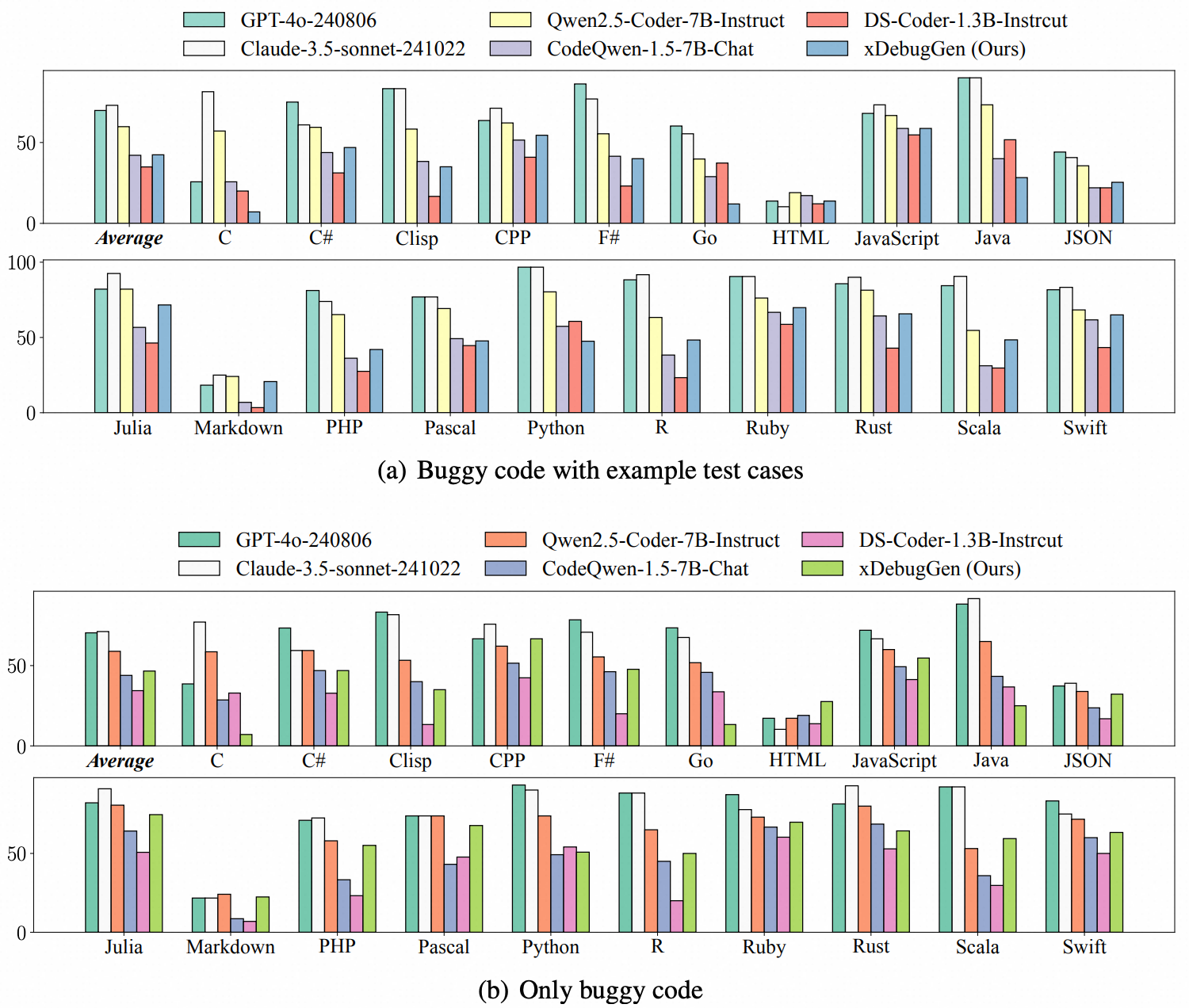
wo additional automated program repair settings are designed to simulate realistic user queries. Part (a) presents results for the scenario where models are provided with buggy code along with example test cases, while Part (b) illustrates results for the scenario where only the buggy code is provided to the models.
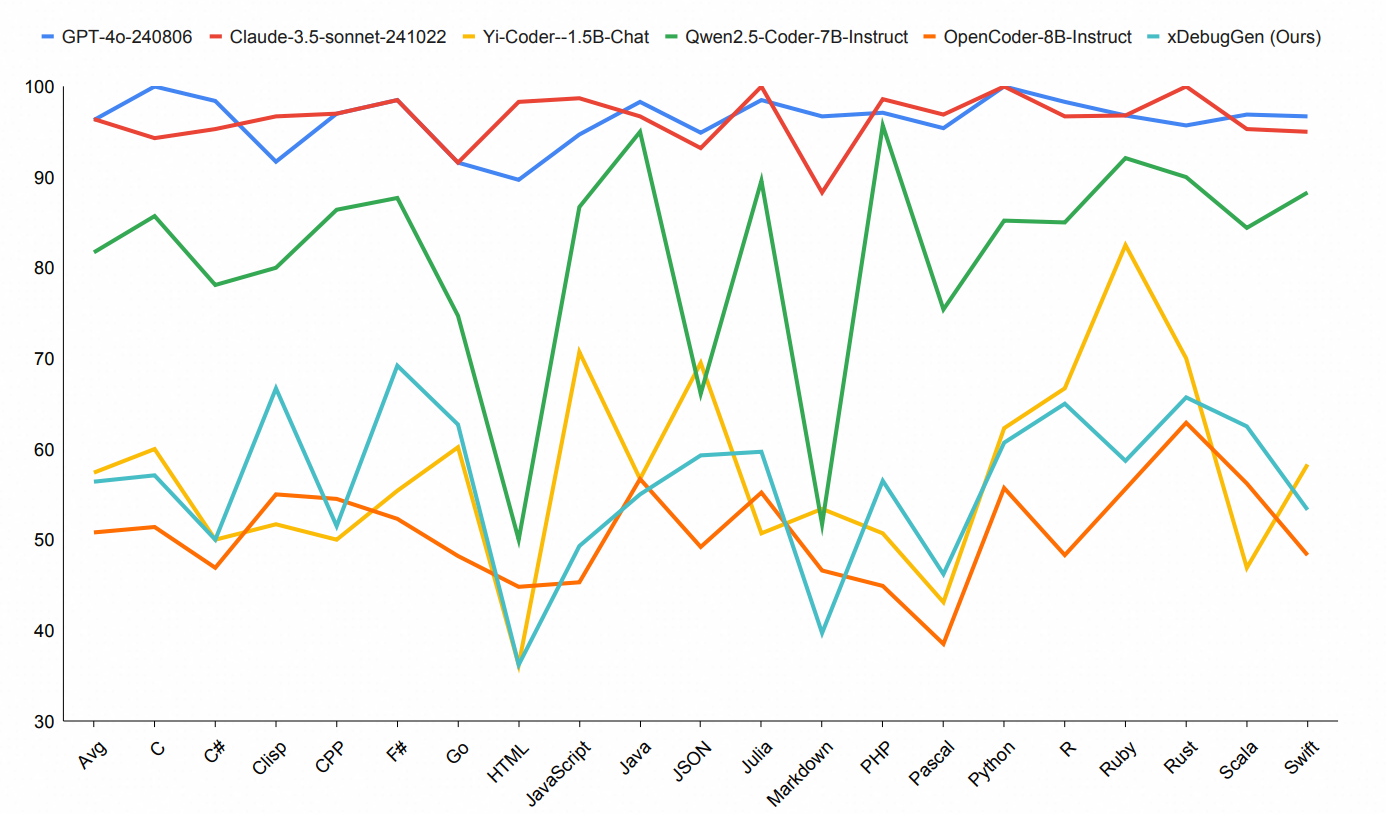
Besides automated program repair tasks, code review tasks also play a crucial role in software development. To analyze the performance of different models on code review tasks, we conducted experiments based on MdEval.
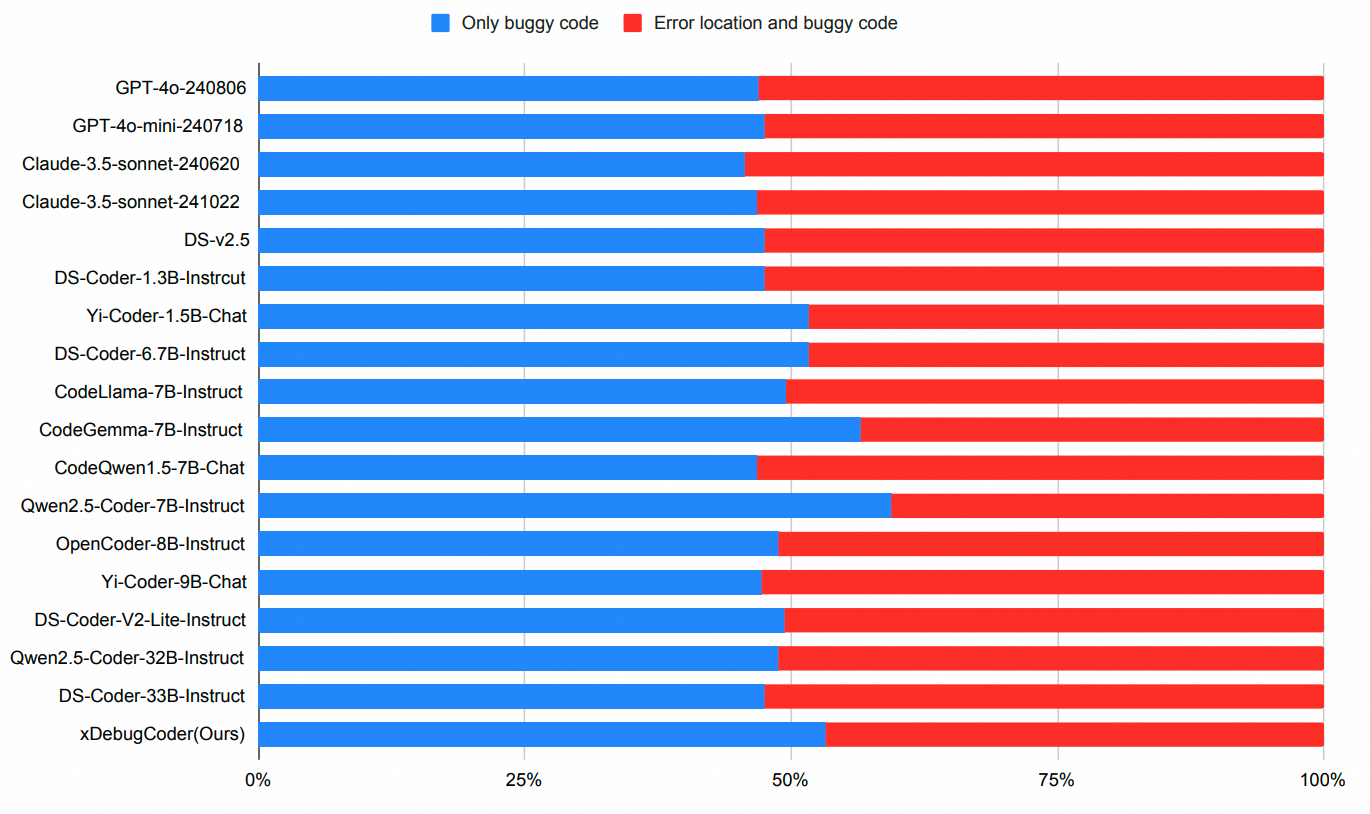
To verify whether the bug location information can have a positive impact when using large language models for automated program repair, we designed and conducted a series of comparative experiments. The figure shows the Pass@1 (%) scores with only the buggy code provided versus when additional bug location information is supplied.